
STM32 - DMA часть вторая

Здравствуйте.
Это продолжение про DMA, начало там.
Предыдущая часть закончилась на режиме
GPIO
С помощью DMA можно за одну транзакцию включать/отключать GPIO-порт целиком или отдельные ножки. Собственно это можно делать и без DMA, но с DMA можно «прикрутив» таймер в качестве триггера (источника запросов к DMA) получить ШИМ сразу на всём порту. Или не на всём, можно на одной, двух, трёх ножках, или со сдвигом по фазе, в общем как заблагорассудится.
порт
На всякий случай поясню что такое порт GPIO. Ножки микроконтроллера разделены на несколько портов обозначенных буквами — GPIOA, GPIOB, GPIOC и т.д. в зависимости от общего количества ножек у микроконтроллера.
К каждому порту привязано не больше 16 ножек, может быть меньше. Названия ножек соответствуют букве порта, например, к GPIOA привязаны ножки РА0-РА15, к GPIOB РB0-РB15, и т.д. Сами буквы как-бы намекают — РB15 — Port B 15.
У каждого порта есть несколько 32-х битных регистров, отвечающих за настройки и функции порта. У регистров которые соединены с ножкой(если выражаться предельно упрощённо) , например регистр ODR, используется только половина бит — с 0 по 15, поэтому то и номера ножек с 0 до 15, остальные биты (с 16 по 31) зарезервированы.
Чтобы подать «плюс» на ножку РА0 настроенную как GPIO Output нужно в нулевой бит регистра ODR (output data register) записать единичку…

Если нужно узнать в каком состоянии сейчас ножка, тогда нужно прочитать этот бит.
Есть ещё регистры BRR и BSRR для атомарного управления портом, но статья не об этом.
Если ножка РА0 настроена как GPIO Input, тогда чтоб узнать её состояние нужно прочитать нулевой бит в регистре IDR (input data register)…

К каждому порту привязано не больше 16 ножек, может быть меньше. Названия ножек соответствуют букве порта, например, к GPIOA привязаны ножки РА0-РА15, к GPIOB РB0-РB15, и т.д. Сами буквы как-бы намекают — РB15 — Port B 15.
У каждого порта есть несколько 32-х битных регистров, отвечающих за настройки и функции порта. У регистров которые соединены с ножкой
Чтобы подать «плюс» на ножку РА0 настроенную как GPIO Output нужно в нулевой бит регистра ODR (output data register) записать единичку…

Если нужно узнать в каком состоянии сейчас ножка, тогда нужно прочитать этот бит.
Есть ещё регистры BRR и BSRR для атомарного управления портом, но статья не об этом.
Если ножка РА0 настроена как GPIO Input, тогда чтоб узнать её состояние нужно прочитать нулевой бит в регистре IDR (input data register)…

Чтоб продемонстрировать работу этого механизма настроим пару ножек и таймер. Настраиваем РВ14 и РВ15 как GPIO_Output…

Таймер понадобится для того чтобы «толкать» DMA. То есть при каждом переполнении таймер будет делать запрос к DMA, и DMA будет копировать (записывать) 16-ти битное значение в регистр ODR.
Например, если записать в регистр ODR порта GPIOB число 0x4000, которое в двоичном виде выглядит так 0100000000000000, то в четырнадцатый бит
Если сейчас сгенерировать проект и добавить в бесконечный цикл вот такую конструкцию…
/* USER CODE BEGIN WHILE */
while (1)
{
GPIOB->ODR = 0b0100000000000000; // оно же в hex 0x4000, оно же в dec 16384, оно же сдвиг (1 << 14)
HAL_Delay(200);
GPIOB->ODR = 0b1000000000000000; // оно же в hex 0x8000, оно же в dec 32768, оно же сдвиг (1 << 15)
HAL_Delay(200);
}… то светодиоды подключённые к РВ14 и РВ15 начнут весело перемигиваться. Это просто демонстрация записи в регистр GPIO, для работы не понадобится.
Приставка «0b» сообщает компилятору что число представлено в бинарном формате.
Теперь настроим таймер как измеритель интервалов времени…

Включаем тактирование таймера и делаем так чтоб он переполнялся каждые 200мс.
DMA…

Запрос к блоку DMA будет происходить во время переполнения — TIM1_UP. Направление передачи из массива в регистр ODR. Размерность данных Half Word. Регистр ODR 32-ух битный, но поскольку используется в нём только первые 16 бит, мы будем передавать полслова.
В программе создаём массив из двух значений, тех же самых, которые использовались в примере выше, только в hex формате…
/* USER CODE BEGIN 2 */
uint16_t buff[2] = {0x4000, 0x8000};Прописываем основную функцию…
HAL_DMA_Start_IT(htim1.hdma[TIM_DMA_ID_UPDATE], (uint32_t)buff, (uint32_t)&GPIOB->ODR, 2);Это та же самая функция, что использовалась в прошлой части для копирования из памяти в память. Отличия в том, что здесь первый аргумент указывает не просто на канал DMA, а на структуру связывающую таймер с каналом DMA, и сообщающую что запрос к DMA должен происходить во время переполнения (TIM_DMA_ID_UPDATE).

Оставшиеся аргументы это указатель на буфер, указатель на регистр ODR, размер буфера.
заметка
Если бы мы хотели чтоб запрос к DMA происходил во время другого события, например, сравнения или какого-то триггера, тогда нужно указать что-то из этого списка...
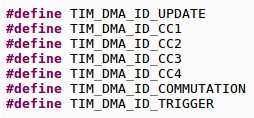
Файл stm32f1xx_hal_tim.h.
В Кубе, в разделе DMA Request тоже нужно указать соответствующий пункт.

Файл stm32f1xx_hal_tim.h.
В Кубе, в разделе DMA Request тоже нужно указать соответствующий пункт.
И добавляем два макроса: инициирующий работу таймера с DMA и запускающий его…
__HAL_TIM_ENABLE_DMA(&htim1, TIM_DMA_UPDATE);
__HAL_TIM_ENABLE(&htim1);Убирайте код из бесконечного цикла, который демонстрировался в начале и прошивайте. В результате мы получим ту же мигалку, только аппаратную. При каждом переполнении таймера, в регистр ODR засылается то одно, то другое значение из буфера.
Если изменить буфер вот так…
uint16_t buff[2] = {0x0000, 0xFFFF};Тогда регистр ODR будет попеременно полностью заполнятся единичками или нолями, то есть будет мигать весь порт. Это легко проверить если настроить другие ножки порта 'B' как GPIO Output и подключить лампочки.
Если у таймера уменьшить предделитель, например до 71, а переполнение сделать 99, то получим аппаратный ШИМ на всём порту с частотой 5КГц и коэффициентом заполнения 50%.
Если сделаем такой буфер…
uint16_t buff[4] = {0x0000, 0x0000, 0x0000, 0xFFFF};… то получим ШИМ с частотой 2.5КГц и коэффициентом заполнения 25%.
В общем изменяя настройки таймера и создавая хитроумные буферы, можно делать ШИМы со сдвигом фронтов или ещё что-нибудь. Более того, сюда ещё можно добавить режим
Сделать это очень просто, нужно добавить ещё один канал DMA…

Источником запросов к DMA будет сравнение на первом канале.
В код добавляем запуск этого хозяйства…
uint16_t buff2[2] = {5000, 30000};
HAL_TIM_DMABurst_MultiWriteStart(&htim1, TIM_DMABASE_ARR, TIM_DMA_CC1, (uint32_t*)buff2, TIM_DMABURSTLENGTH_1TRANSFER, 2);Изменяем только один регистр — ARR. Источник запросов сравнение — TIM_DMA_CC1.
Всё, можно прошивать.
Сейчас функция
Про GPIO и DMA хочется сказать ещё несколько слов. Записывать данные в регистры GPIO можно и без всякого таймера, правда смысла в этом особого нет, но тем не менее это весьма полезная информация в целом.
Удалите в Кубе все настройки связанные с DMA и настройте его на копирование из памяти в память…

Направление передачи из памяти в память, другого варианта нет, однако регистр GPIO это по сути периферия, и в прошлом примере мы записывали данные в GPIO как в периферию, а сейчас у нас включён режим Memory To Memory. Возникает вопрос — как же так, а ответ очень прост, настройки Memory To Memory, Memory To Peripheral, Peripheral To Peripheral, это просто формальность. Как я уже писал в первой части — что бы мы не делали в микроконтроллере, это всего лишь запись единиц и ноликов в определённые ячейки памяти.
В функцию инициализации DMA прописываем циклический режим — DMA_CIRCULAR…

И запускаем процесс…
/* USER CODE BEGIN 2 */
uint16_t buff[] = {0x4000, 0x0000};
HAL_DMA_Start(&hdma_memtomem_dma1_channel1, (uint32_t)buff, (uint32_t)&GPIOB->ODR, 2);Отличие от предыдущего примера только в первом аргументе.
Лампочка будет светить в полнакала. DMA меняет бит в регистре со всей возможной скоростью. До этого у нас таймер рулил скоростью, а сейчас оно жарит «на всю катушку».
Если замерить частоту на пине то получим около 3.6 МГц, что в общем то не так уж и много.
Если делать то же самое только без DMA…
/* USER CODE BEGIN WHILE */
while (1)
{
GPIOB->ODR = 0x4000; // 0b0100000000000000
GPIOB->ODR = 0x0000; // 0b0000000000000000
}… тогда получим частоту около 12 МГц.
Если нечем замерить частоту, тогда воспользуйтесь этой статьёй чтоб превратить вашу плату в частотомер — будет сама себя измерять.
Не забывайте включать DMA_CIRCULAR после перегенерации проекта.
С DMA…

Без DMA…

Выводы таковы: мнение о том, что
Для пущей убедительности прочтите эту статью, не пробегитесь глазами, а прочитайте внимательно, там человек проводил исследование DMA (там есть глава про stm32) и сделал очень полезные выводы.
Однако не всё так однозначно. Например если копировать большой объём данных конкретно из памяти в память, тогда DMA существенно выигрывает в скорости. Собственно у меня получилось, что при копировании свыше 100 байт и больше, DMA копирует в два раза быстрее. Эксперимент проводился в идеальных условиях, то есть ничего больше программа не делала.
Для измерения использовался DWT…
/* USER CODE BEGIN 2 */
#define BUFFSIZE 14 // размер буфера
volatile uint8_t src_buff[BUFFSIZE] = {0,}; // два буфера
volatile uint8_t dst_buff[BUFFSIZE] = {0,};
char trans_str[32] = {0,};
uint32_t count_tic = 0;
//////////////////////// копируем вручную ////////////////////////////////
CoreDebug->DEMCR |= CoreDebug_DEMCR_TRCENA_Msk;// разрешаем использовать DWT
DWT->CTRL |= DWT_CTRL_CYCCNTENA_Msk; // включаем счётчик
DWT->CYCCNT = 0;// обнуляем значение
for(uint16_t i = 0; i < BUFFSIZE; i++)
{
dst_buff[i] = src_buff[i];
}
count_tic = DWT->CYCCNT; // сколько натикало
snprintf(trans_str, 63, "MAN %lu tiks\n", count_tic);
HAL_UART_Transmit(&huart1, (uint8_t*)trans_str, strlen(trans_str), 1000);
//////////////////////// копируем через DMA ////////////////////////////////
count_tic = 0;
DWT->CYCCNT = 0;
HAL_DMA_Start(&hdma_memtomem_dma1_channel1, (uint32_t)src_buff, (uint32_t)dst_buff, BUFFSIZE);
while(!(DMA1->ISR & DMA_FLAG_TC1)){} // дожидаемся окончания копирования
count_tic = DWT->CYCCNT; // сколько натикало
snprintf(trans_str, 63, "DMA %lu tiks\n", count_tic);
HAL_UART_Transmit(&huart1, (uint8_t*)trans_str, strlen(trans_str), 1000);
/* USER CODE END 2 */Копируется 14 байт, сначала вручную, потом через DMA…

20 байт…

100 байт…

В два раза быстрее.
Если в функции DMA получателем сделать GPIO…
HAL_DMA_Start(&hdma_memtomem_dma1_channel1, (uint32_t)src_buff, (uint32_t)&GPIOB->ODR, BUFFSIZE);Тогда получим вот такой результат…

Так как GPIO это уже другая шина, то скорость упала с 692-х тиков до 1091.
про BSRR
Я намеренно не использовал регистры BSRR и BRR так как для примеров было достаточно ODR, однако ничто не мешает работать таким же образом с BSRR. Для этого нужно в настройках DMA указать длину слова WORD (32 бита), и изменить размер элементов буфера…
Элементы буфера надо подобрать такие, чтоб каждый из них мог включать какие-то биты, а какие-то отключать. Например число 0x90000101 (10010000000000000000000100000001) одним махом включит 0-ой и 8-ой биты, и отключит 12-й и 15-й. Таким образом с помощью одного элемента буфера можно будет не только включать и отключать определённые биты одновременно, но ещё и не затрагивать все остальные биты в регистре ODR.
В функции нужно изменить только регистр…
Это применительно ко всем выше описанным примерам.
uint32_t buff[2] = {0,};Элементы буфера надо подобрать такие, чтоб каждый из них мог включать какие-то биты, а какие-то отключать. Например число 0x90000101 (10010000000000000000000100000001) одним махом включит 0-ой и 8-ой биты, и отключит 12-й и 15-й. Таким образом с помощью одного элемента буфера можно будет не только включать и отключать определённые биты одновременно, но ещё и не затрагивать все остальные биты в регистре ODR.
В функции нужно изменить только регистр…
HAL_DMA_Start(&hdma_memtomem_dma1_channel1, (uint32_t)buff, (uint32_t)&GPIOB->BSRR, 2);Это применительно ко всем выше описанным примерам.
ADC
Вначале я хотел здесь описать работу АЦП c DMA, но потом решил что не стоит дублировать информацию, которая рассказывает об этом в статье про АЦП. Тем более, что это трудно сделать без описания нюансов работы АЦП, поэтому добро пожаловать сюда.
Всего написанного выше вполне достаточно для полноценного использования DMA, однако надо рассказать про устройство DMA у некоторых камней из серии F2, F4 и F7. Оно несколько сложнее, и есть дополнительный функционал, но в целом суть работы остаётся прежняя.
FIFO
Вот так выглядит схема двух контроллеров DMA у F4…

Рис. 1.
А вот так выглядит один из этих контроллеров крупным планом…

Рис. 2.
Восемь REQ_STREAMx
Например, если пришёл запрос REQ_STREAM1, то соответственно запускается поток STREAM 1
На рис. 1 видно что у DMA контроллера №2, порты Memory и Peripheral, соединяются через Bus matrix
Channel selection на рис. 2 слева, это восемь мультиплексоров к которым подключены по восемь каналов (REQ_STRx_CHх) для отправки запросов от различной периферии. Один мультиплексор выглядит так…
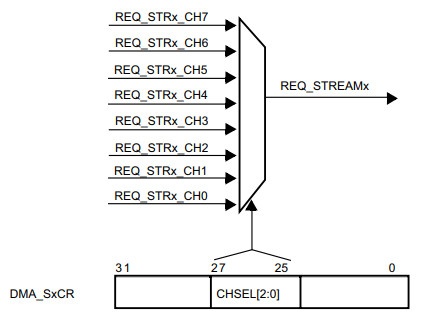
Только один канал может быть активирован на одном мультиплексоре, и соответственно соединён с REQ_STREAMx.
Для сопоставления каналов и потоков, в мануалах на конкретный камень есть таблицы. Например…

Таким образом, например, получение данных от ADC1 на канале №0 первого мультиплексора, через поток №0 (STREAM0), будет выглядеть так…

По
на общей схеме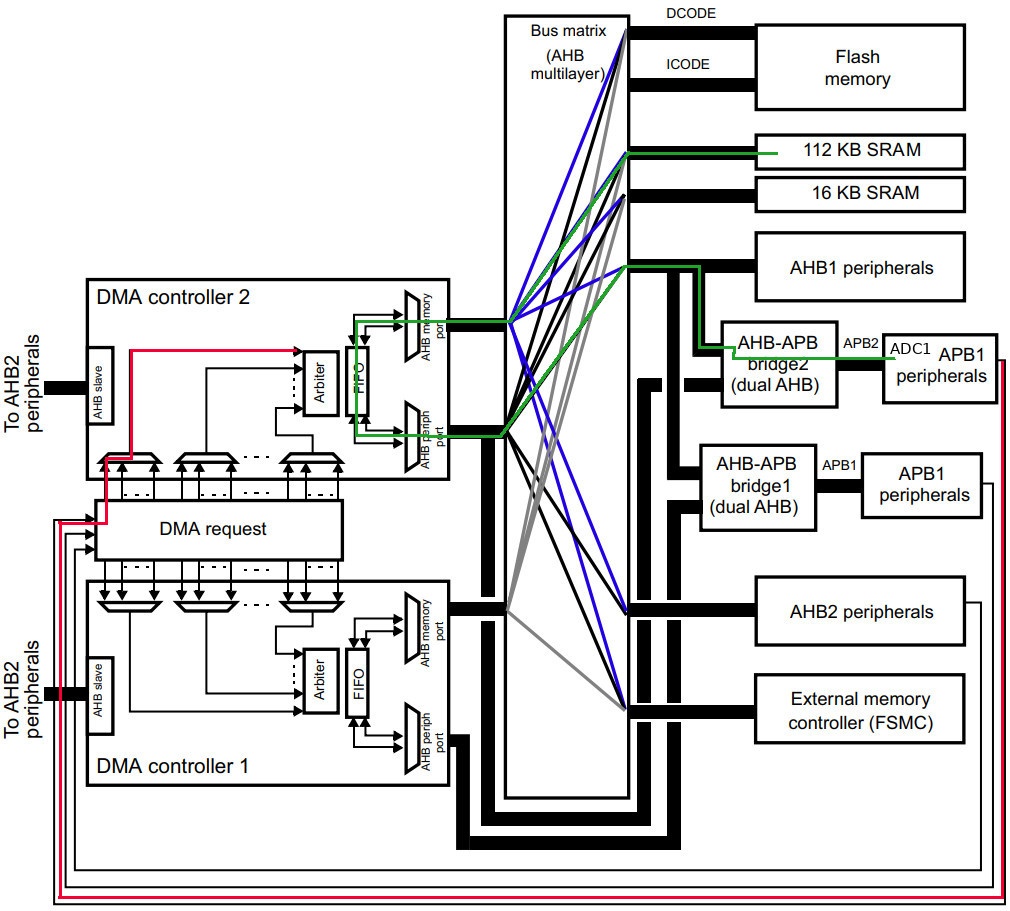

Так же мы могли бы настроить ADC1 на передачу данных по четвёртому потоку (STREAM4), тогда запрос бы приходил через нулевой канал четвёртого мультиплексора —
Если бы при ADC1 работающем через нулевой поток, нам понадобилось бы запустить SPI1_RX, тогда пришлось бы воспользоваться STREAM2, так как два устройства не могут работать на одном потоке. Думаю суть понятна, ну а если настраиваете в Кубе, то и вовсе не о чём парится, он всё сделает сам.
У каждого потока есть свой буфер FIFO, то есть у каждого контроллера DMA есть восемь независимых FIFO. Размер каждого FIFO равен 4х32 бита, то есть 16 байт. Выглядит буфер так…

В буфер можно помещать данные либо целыми словами (32 бита), либо полусловами (16 бит), либо байтами (8 бит). Заполнять буфер можно (вертикальные колонки) на четверть, на половину, на три четверти, или полностью. На картинке буфер заполнен полностью байтами. Обратите внимание, что на вход подаются байты, и выходят тоже байты, однако можно делать по разному, заполнять байтами, а забирать байты, полуслова или целые слова, можно заполнять полусловами, а забирать байты, полуслова, или целые слова. Можно заполнять целыми словами, а забирать байты, полуслова, или целые слова, в общем можно делать как угодно исходя из задачи. Смотрите…
картинку из мануала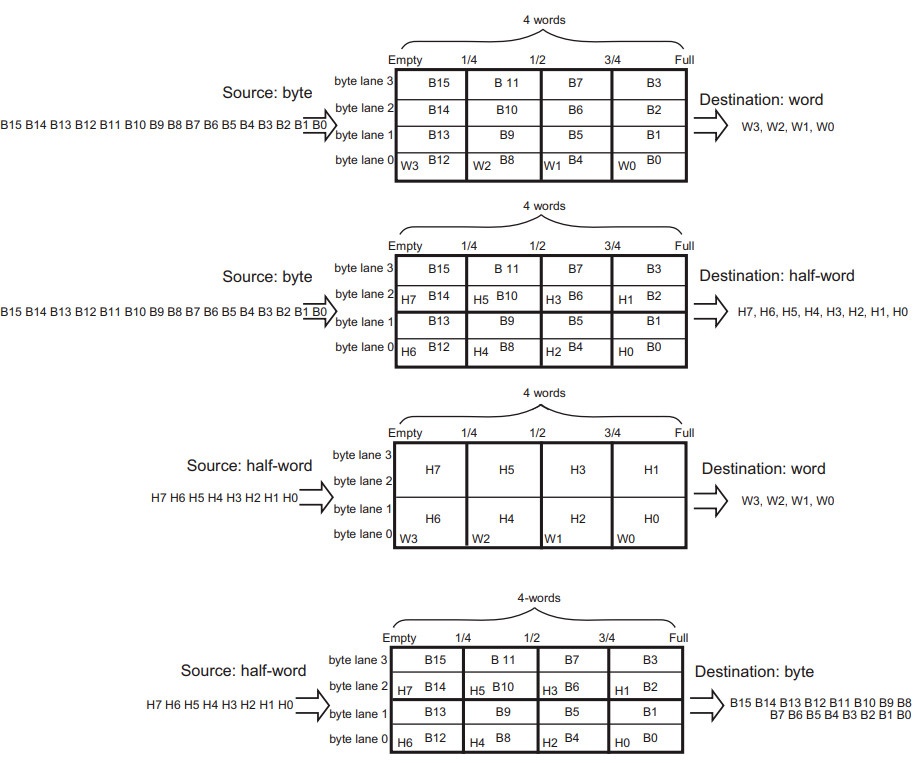

Суть буфера заключается в том, чтобы разгрузить шину AHB. Объяснить это лучше на примере поэтому вернёмся к ADC1. Когда буфер FIFO отключён…

… тогда данные из АЦП передаются в память напрямую, как будто буфера нет. Это называется прямой режим.
Предположим что АЦП занимается преобразованием непрерывно, и соответственно получается, что шина занята и чтением из АЦП, и перекладыванием полученных данных в память практически одновременно.
Если же включить FIFO…

… тогда данные поступающие от АЦП будут заполнять буфер, и пока буфер не заполнится, эти данные не будут передаваться в память. Таким образом шина
Теперь, помните я в самом начале говорил про DMA-burst (пакетная передача данных), так вот, пункт
Если мы сейчас запустим процесс, то будет происходить следующее: АЦП после каждого преобразования будет посылать запрос к DMA чтоб тот забрал очередной результат. DMA будет забирать результаты и складывать их в FIFO до тех пор пока FIFO не заполнится (в память результаты не будут пересылаться). Как только FIFO заполнится, так сразу же эти результаты начнут перекладываться в память. Так вот, поскольку у нас сейчас в настройках указано
Но, дело не только, и не сколько в тактах, а в том, что между передачами могут происходить задержки из-за того, что ресурсы Bus matrix и других шин будут передаваться в распоряжение ЦПУ. В данный момент эти задержки не страшны, так как DMA работает в нормальном режиме, а вот если бы был включён циклический режим (Mode ⇨ Circular), и АЦП опрашивалось бы непрерывно, тогда могло случится так, что из-за задержек FiFO бы не успевал вычитываться, что привело бы к ошибкам.
Так вот, чтоб такого не происходило, был придуман пакетный режим, суть которого заключается в том, что после заполнения FIFO, перед началом передачи из FIFO в память, DMA говорит, — «я занимаю шину на такое-то количество транзакций, прошу никого не мешать мне работать». И всё, после этого DMA быстренько перекладывает данные из FIFO в память безраздельно властвуя над шиной.
Настраивается это так…

В разделе
Если мы оперируем целыми словами…

… тогда размер пакета не может быть больше 4 значений, так как FIFO не может содержать больше 4 слов.
Если бы мы оперировали байтами…
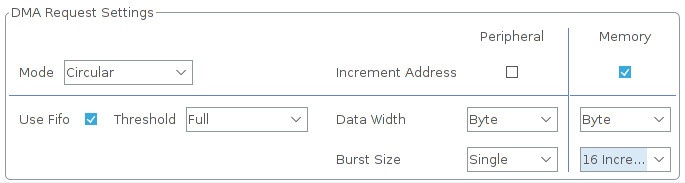
… тогда размер пакета может быть 4, 8 или 16 значений, и соответственно передачи смогут осуществляться за четыре, за два, и за один заход.
Если мы сейчас захотим уменьшить FIFO до половины (Threshold ⇨ Half Full), то Куб не даст нам это сделать пока мы не уменьшим размер пакета до восьми или четырёх Increment, так как размер пакета не может быть больше чем количество данных в FIFO.
Как вы уже поняли, при работе с FIFO всё взаимосвязано, и размер FIFO
Помимо этого FIFO умеет запаковывать/распаковывать данные. Допустим нам надо забирать откуда-то байты, а пересылать их куда-то уже в виде полуслов…

FIFO позаботится о том, чтоб полученные байты вычитывались из буфера как полуслова, с соответствующим инкрементом памяти. Это называется запаковка. Так же можно запаковывать байты в слова или полуслова в слова. То же самое можно делать и наоборот, это будет называться распаковкой. Пакетную передачу тоже можно использовать. Так же нужно понимать, что в режиме запаковки/распаковки необходимо соблюдать кратность данных, то же самое касается работы с FIFO в целом.
К сожалению я не проверял работу с FIFO так как у меня нету платы с таким функционалом (если кому не жалко, киньте немного доната), всё выше написанное это выводы из прочитанного в мануалах. Собственно поэтому и объяснения могут показаться несколько расплывчатыми, а где-то могут оказаться и не совсем точными. Впрочем здесь не только моя вина, сами мануалы написаны так, что порой не заешь как трактовать те или иные вещи, а важным деталям не уделяется должного внимания.
Double buffer
Режим двойного буфера:
В режиме периферия-память
В режиме память-периферия

Режим двойного буфера работает только в циклическом режиме DMA (Mode ⇨ Circular). Массивы должны быть одинаковых размеров.
Функция для запуска выглядит так…
HAL_DMAEx_MultiBufferStart(DMA_HandleTypeDef *hdma, uint32_t SrcAddress, uint32_t DstAddress, uint32_t SecondMemAddress, uint32_t DataLength)Самое интересное в этой функции, это то, что совершенно не понятно как её использовать

Единственное что приходит в голову, на примере отправки данных по USART'у через DMA, это в функции
Не знаю, может я конечно где-то что-то упустил, но с другой стороны, можно предположить, что эту функцию не стали доводить до ума так как по сути тот же функционал выполняет прерывание по половине DMA.
Тем не менее, эта непонятка относится только к работе с библиотекой HAL, если же делать на CMSIS, то оно работает. Во всяком случае в сети есть пример, где человек это проделывал.
Ещё есть функция (дополняющая выше описанную) для смены адреса памяти…
HAL_DMAEx_ChangeMemory(DMA_HandleTypeDef *hdma, uint32_t Address, HAL_DMA_MemoryTypeDef memory)Менять адреса можно на лету, но с условием:
Первый адрес можно менять когда бит CT в регистре DMA_SxCR равен 1.
Второй адрес можно менять когда бит CT в регистре DMA_SxCR равен 0.
Этого я тоже не проверял, по тем же причинам.
Инфа:
AN4031 стр. 6.
AN4031 — перевод через онлайн переводчик.
RM0090 стр. 304.
Частичный перевод на русский.
DMAMUX
Этот функционал есть у STM32H7, STM32G0, STM32L4+ и STM32WB.
DMAMUX — это мультиплексор позволяющий выбирать какую периферию к какому каналу подключать. Так же умеет запускать передачу данных по триггеру от таймера №12 или по внешнему прерыванию. Так же запрос на одном канале может запускать другой канал. В общем вносит больше гибкости в работе с DMA.
Описывать это я не буду так как там вроде ничего сложного нет, и нужно пробовать на железе, которого у меня опять таки нет.
Вся необходимая инфа тут — AN5224.
Ещё у микроконтроллеров старших серий есть штуковина по названием DMA2D, это графический ускоритель Chrom-ART для TFT-LCD-дисплеев работающий по технологии DMA. Но это уже совсем другая история.
В довершение статьи хочется сказать, что DMA это не волшебник, он не делает всё быстрее по мановению палочки. Каждая транзакция требует дополнительных тактов на запрос и арбитраж для доступа к шине, на вычисление адреса, на одиночную передачу, и наконец на подтверждение передачи. DMA и CPU выступают в качестве хозяев Bus matrix, однако когда им обоим потребуется одновременный доступ к одному и тому же ресурсу, Bus matrix отдает приоритет CPU. Это не значит что DMA будет «выкинуто на мороз», просто оно запустится чуть позже. Максимально возможная задержка зависит от количества мастеров, осуществляющих доступ к ресурсу, а также от количества каналов, настроенных на конкретном DMA. Подробнее про всё это лучше почитать в мануале, так как там много нюансов связанных с работой шин.
Это всё, всем спасибо
 Собираю донаты на хорошенькую F7, чтоб можно было экспериментировать в статьях со всем чем только возможно.
Собираю донаты на хорошенькую F7, чтоб можно было экспериментировать в статьях со всем чем только возможно.Да, вот ещё пара любопытных ссылок — раз и два.
Телеграм-чат istarik
Телеграм-чат STM32

- 0
- stD

53360

Поддержать автора
Комментарии (0)